Learning to write a proper Axon application from scratch consists of various aspects. First, there's the conceptual stuff to grasp (DDD, event sourcing, CQRS) and details about the actual framework (which dependencies to include, annotations to use). After you've grasped the basics (perhaps doing the quick start), the reference guide will guide you further. Another good place to start is our upcoming webinar.
However, talking with AxonIQ customers, I found out that there's something we may need to be a little more clear about: What does the general structure of a real-life Axon application look like? What goes where, and how do you prevent a mess? In this blog, I'll try to shed some light on this topic.
Domain model and adapters
First of all, Axon is heavily inspired by domain-driven design (DDD). Some DDD concepts are an essential part of the framework (aggregate, domain event, repository). In contrast, others are not explicitly but should nevertheless be part of your thinking (anti-corruption layer, value object, entity, bounded context).
Classic texts on the subject are from Eric Evans and Vaughn Vernon. Both come highly recommended. Personally, I think Vaughn’s book is more practical and an easier read. However, it has loads of stuff relevant to building an Axon application, and I would highly recommend studying it. Below, I’ll try to cover a few key DDD ideas that directly affect how you should structure an Axon application.
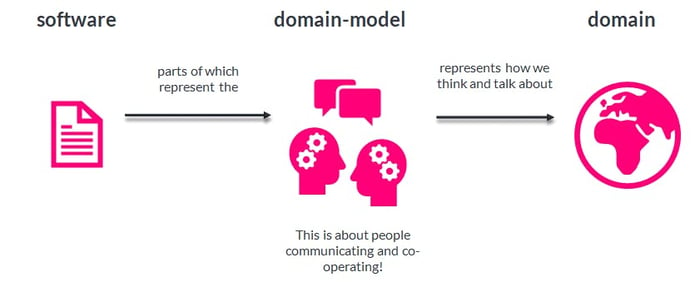
The core notion of DDD is, of course, the domain. The domain is not a Java package or similar. It’s a sphere of activity in the real world, like, for instance, “pizza delivery.” We assume we’re building an application to support processes in such a domain. We as developers won’t fully understand the domain upfront in realistic situations, so lots of communication with domain experts is necessary. In that way, we’ll end up with a shared domain model. Again, not code yet, but we’re getting closer. A core idea of DDD programming is that you construct the software so that part of it is a faithful implementation of the domain model. In complex domains, this will lead to much more maintainable and reliable software than software is written using alternative approaches, like transaction scripts operating on data structures.

For an Axon application, this means the following: a clearly separated area of your source code (like a package or sub-project) should be devoted to implementing your domain model and nothing else. Your domain model will also communicate with the outside world (for instance, it might receive HTTP requests and send out emails). The technicalities of these links should not be in the domain model simply because they aren’t part of the domain model. You need to prevent your domain model code from being influenced by this by putting the integration code in adapter classes outside your domain model. These classes should not contain business logic (that belongs in the domain model) but translate representations.
Domain model representation: API
Axon assumes an approach where interaction with the domain model takes place through explicit message objects. The messages belong to one of 3 stereotypes: commands, events, or queries. Adapters can send these messages to the domain model by publishing them on the corresponding bus or listen to them by having a handler registered on the bus. For commands and queries, messages are usually sent through the gateway, which is an easy way to use a facade on the bus.
This approach implies that the commands, events, and queries are the API to your domain model. There will be all kinds of other stuff on the domain model side, probably at the very least some aggregates. From an adapter perspective, that’s all implementation and not directly accessible.
Importantly, between multiple (micro)services using Axon, communication can happen directly (using Axon Server or another distributed bus implementation). Adapters, like described previously, are required to make Axon-based domain model representations interact with the outside world but are entirely redundant to exchange commands, events, and queries between Axon-based components.
In any serious Axon application, you’ll have quite a lot of these commands, events, and queries. From a DDD perspective, these are value objects: immutable values, without any form of the life cycle, for which the equality of their fields determines equality. Technically, we’re talking many private final fields, an all-arg constructor (possibly a builder), getters, toString, equals, and hashcode. Explicitly coding all of this in Java is hardly an option. Axon practitioners usually rely on Lombok (@Value), Kotlin (data classes), or sometimes Scala (case classes) to drastically reduce this boilerplate. Kotlin, in particular, may easily be mixed with Java if you want to use it for this purpose without adopting Kotlin for everything.
A thing to note about these value objects is that they will be shared between Axon components in serialized form (using the serializer you configured). So whether or not you share the actual value object classes between separate but communicating Axon projects is a matter of choice.
Domain model representation: implementation
On the domain model implementation side, you’re going to have components that react to incoming commands, events, and queries and/or produce them. A key example of this is an event-sourced aggregate that may consist of one or more entities. Aggregates listen to commands and produce events.
Another type of component usually found in an Axon application is a projector (which is responsible for creating projections, also called read-models). It listens to both events and queries. In response to events, it will update its data store to give accurate answers to queries after that. This is a core component of CQRS.
Several other components may exist as well. Sagas respond to events, have stated, and send out commands, managing transactions, and business processes. In addition, there may be stand-alone handlers of any type (domain services), implementing business logic and possibly publishing new messages of any type.
Any code you have in this part of your software should be there because it represents the domain model. Stuff that is totally recognizable to non-programming domain experts. If you feel the need to include a certain thing because it is necessary technically without being part of the domain model, re-think or put it somewhere else.
Taking into account what we said about the API and the implementation of the domain model, we’re now in a position to sketch a more detailed diagram of the overall structure of an Axon application:
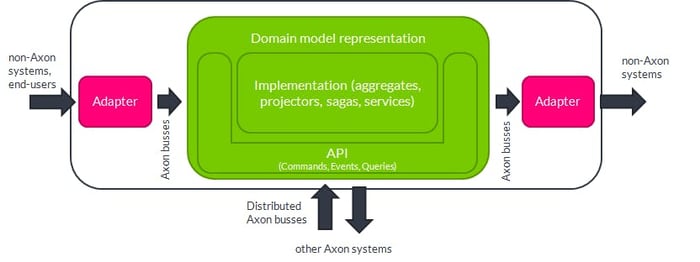
Putting it all together
Above, we’ve sketched the various areas of a full Axon application but didn’t specify how to separate these areas. Axon doesn’t enforce anything here. It may be done through Java packages or even Java 9 modules. A little bit stricter, the various areas could be split into separate modules of a single application. And you may go further: with Axon, all exchange of commands, events, and queries is location-transparent, so the various objects that make up the domain model implementation, as well as the adapters, can run as separate microservices without code changes!
Because you have all of this flexibility to split things up in the future, we recommend not to bother too much about this initially when creating an application. Simply choosing the appropriate package structure is a good starting point. Then, splitting up more strictly can be done as soon as it’s justified.
In addition to the areas already described, your concrete Axon application will also contain some Axon configuration code setting up the infrastructure. Axon, in particular when used in conjunction with Spring Boot, has been designed to have very reasonable defaults to make initial development possible without doing any explicit configuration. Nevertheless, real-life applications usually have some specific configuration requirements. Common examples are setting up aggregate snapshots, aggregate caching, and specific serializers. Also, it’s quite common to configure interceptors to implement cross-cutting concerns like authorization and logging. Axon’s busses offer an API to do this as part of your configuration code.
Finally
There’s one topic in this field that we didn’t touch upon yet: what if your Axon system covers multiple domains or bounded contexts? In that case, there will not be a single domain model API but multiple sets of commands, events, and queries. The key point here is that these various models shouldn’t pollute each other. Looking at this in detail is beyond the scope of this blog. Evans Chapter 14 covers it extensively; one particular pattern to be aware of is the anti-corruption layer. Technically, Axon supports (but doesn’t require) explicitly using contexts to separate messages belonging to separate contexts. Thus, anti-corruption layer components would have access to 2 contexts, using 2 separate sets of Axon buses.
We hope the above is useful to Axon practitioners. Feel free to reach out to us with any questions or comments!

