There are several situations where you might want to copy or move the contents of your Event Store, not just to build a view model but to either move events to a new system or perform large-scale conversions on the contents. Quite often, an Axon Server-based Event Store can be moved using a simple file copy. Still, what if this isn’t possible, we’re moving between different event store implementations, or we only want a selection of the contents?
In this blog, we’ll look at some of the scenarios and the different approaches available.
Scenario 1: Moving from Axon Server to Axon Server
Suppose you started with Axon Server Standard Edition and want to move toAxon Server Enterprise Edition to take advantage of the enhanced Availability or Security options, then how to transfer the Event Store may not be an obvious path, especially if you want to use the multi-context feature to consolidate several SE installations. Although the simple path is based on file copies, you may have a problem if the current installation does not give you easy access to the underlying file system. This situation may also arise when moving from a local disk using Kubernetes cluster to one using Network or Cloud storage or moving to a VM-based installation. Let’s start with the simplest scenarios and look at how events and snapshots are stored.
Note: Most of what is discussed here is largely relevant for recovery scenarios and should not be applied in those situations without careful consideration. Trying to get Axon Server back up and running after you lost part or all of its event stores should include steps to minimize the actual changes applied, to prevent data loss. In a migration scenario, we can assume clean shutdowns and an empty target event store.
The Axon Server Event Store
Events and snapshots in Axon Server are stored in pre-allocated files on disk, which means they are administratively created at a certain size, even though no actual contents have been stored yet. On the filesystem, this uses a facility called “sparse files,” where an index is kept of actual blocks of data that have been written while the untouched parts are left absent. In practice, this means you could have a file announced as being 256MiB in size, while in actuality, using no data other than that of the directory entry. Write some bits and bobs to a few random locations within those claimed megabytes, and the size remains unchanged, while the disk usage has increased to cover those bits and bobs, rounded up to account for the actual blocks of data often in multiples of 512 bytes. Copy the file, however, and you’ll get the full size both in shown and used size because it’ll behave as if all the data is there, just mostly zeroes, which luckily compresses nicely. For Axon Server, the situation is simpler, as it does no random walk through the file but adds data from the start until the next bit no longer fits the limit of the configured segment size.
Axon Server, by default, creates its Event Store in the “data” subdirectory of where it’s living, together with the Control Database (a file named “axonserver-controldb.mv.DB”), using one subdirectory per context. Axon Server SE has only a single context, and it is named “default,” while EE has a directory per context, and in those directories, you’ll see numbered files. Files ending in “.events” are used to store events, while those ending in “.snapshots” contain, you guessed it, the aggregate snapshots. These files are referred to as “segment files,” and new segments are created automatically when the old ones fill. To enable Axon Server to quickly find data in the older segments, they will have indexes and bloom filters. If these additional files do not exist on startup, they will be created, so if we want to copy the contents of the entire event store, the event and snapshot files are the most important. However, going over a few gigabytes or terabytes of data to recreate indices is a costly activity, so unless we expressly want them recreated, copying them along is best.
Axon Server has a REST API endpoint at “/v1/backup/filenames,” which returns the names of the segment files that have been “closed,” meaning they are not for the current segment. You can also add a parameter to pass the last segment already backed up, so the list will only contain new files added since then. Being a write-only store, we can be assured no changes have been made to the older ones. Also, note that the endpoint will only return the names of the files, not the contents, so we still need to access the underlying disk to get them. The obvious alternative is to use an incremental backup service provided on your storage platform. Please note that if your requirements for disaster recovery cannot be met with only the closed segments, you can actually copy the current segment and have the Control DB backed up to indicate how far Axon Server has progressed. If all three nodes have different ideas about this level of progress in a full-cluster recovery situation, the one with the most confirmed data will be the elected leader and update the others. However, to correctly implement such strict requirements, you’ll also want to backup the Replication Logs, which (in an EE cluster) store the data ready for distribution. It actually contains the most recent changes consolidated for a replication group, so if the group contains more than one context, you will not be able to single out a particular context. The log that all members have confirmed will be regularly cleaned, so the log will generally be pretty small.
To summarize, if your goal is to provide for a backup, you should at the very least copy all closed segments or complete and include the current segment, logs, and Control DB. There are no logs for SE, but the same choice exists for the rest. For an EE-to-EE migration scenario, where you want to use the data to seed a new (different) context, you cannot reuse logs and Control DB, so another tactic must be applied. We’ll get back to that after the next section, which discusses restoring the backup.
Seeding a Context with a Backup
To use the files we have just backed up, we need to copy them to the new server and place them in the correct directory. If this is SE-to-SE or even a straight EE-to-EE copy, you can include the directory itself in the backup and unpack the archive on the other side, but if you want the files to end up in a different context, you only want the files. When Axon Server starts up and the context is already known, it will notice the files and ensure that its understanding of the last segment matches what it sees. If the context is (as yet) unknown, it will ignore the files. When you create the context, it will attempt to create a directory and find the context already filled.
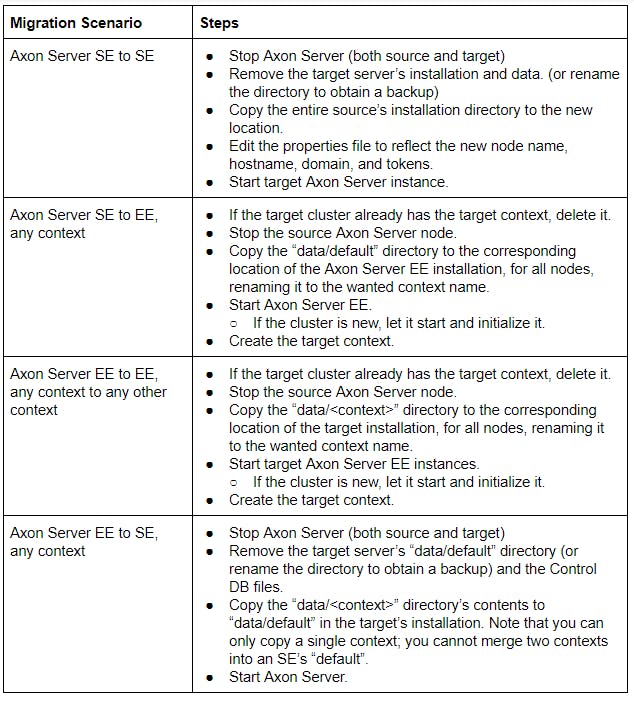
Assuming default directories, the steps classified by the migration scenarios are:
AxonServer SE to SE
Migration Steps:
- Stop Axon Server (both source and target)
- Remove the target server's installation and data (or rename the directory to obtain a backup)
- Copy the entire source's installation directory to the new location
- Edit the properties file to reflect the new node name, hostname, domain and tokens.
- Start target Axon Server instance
AxonServer SE to EE, any context
Migration Steps:
- If the target cluster already has the target context, delete it.
- Stope the source Axon Server node.
- Copy the "data/default" directory to the corresponding location of the Axon Server EE installation for all nodes and rename it to the desired context name.
- Start Axon Server EE. If the cluster is new, let it start and initialize it.
- Create the target Context.
AxonServer EE to EE, any context to any other context
Migration Steps:
- If the target cluster already has the target context, delete it.
- Stope the source Axon Server node.
- Copy the "data/<context>" directory to the corresponding location of the Axon Server EE installation for all nodes, renaming it to the wanted context name.
- Start Axon Server EE. If the cluster is new, let it start and initialize it.
- Create the target Context.
AxonServer SE to SE
Migration Steps:
- Stop Axon Server (both source and target)
- Remove the target server's "data/default" directory (or rename the directory to obtain a backup) and the Control DB files.
- Copy the "data/<context>" directory's contents to "data/default" in the target's installation. Note that you can only copy a single context, you cannot merge two contexts into an SE's "default".
- Start target Axon Server instance
As mentioned, if no index files are present during the initial check, Axon Server will create them. Axon Server uses a scan backward from the before-last segment until a segment with an index is found. Note that you should check that there are no holes and remove all index files after such a hole if you do find one. Another step in the check is for the structural integrity of the last few segments. If Axon Server were shut down cleanly, it would only check the last two segments. If the shutdown was not clean, a configurable number of segments is checked. The property for this is “axoniq.axonserver.snapshot.validation-segments”, and it defaults to 10 segments.
After all, checks have finished, Axon Server will determine the last segment and last position in that segment and record it in the ControlDB. When the next event or snapshot comes in or a heartbeat message is sent from the leader, it compares the new entry’s index with the expected location for the next entry. In case of a mismatch, most likely because it has an incomplete store, it communicates this to the current leader, who will provide the node with any missing data. If “axoniq.axonserver.replication.force-snapshot-on-join” is true, which is the default, the backlog is sent in a more efficient snapshot format (not to be confused with the aggregate snapshots) instead of the “normal” transaction-based packaging. Only when the node is up-to-date will it start partaking in the confirmation of transactions. Note that if you start with only the leader having a complete store, for example, because they all had different opinions about the current state, the cluster will not be functional until most nodes are up-to-date.
Programmatically Transferring Events
If, for whatever reason, you are unable to obtain copies of the Event Store files, but you have a working server (or cluster), you have two alternatives: you can use a “normal” TrackingEventProcessor and stream (a specific kind of) events normally, or you can plug into the (lower-level) event stream directly and get them that way. Both methods will actually let us inspect and optionally transform the events, but neither will include a stream of the snapshots. Note that if you decide to modify the event payload or metadata, do not build a completely new EventMessage object, but only set the changed data on the retrieved one, or you’ll get new message identifiers and timestamps. With a programmatic approach, you also gain the possibility to split a context or even merge two or more. Still, then you need to generate new identifiers to ensure there are no gaps or overlapping segments.
Sometimes, the most straightforward approach is the right one, and writing an event handler to copy events is a pretty simple and easy-to-control method. You have full control over what you do with the events, including the option to make changes to payload or meta-data. However, if you publish the events regularly, you may not get an exact copy because other events may be published in the target context. Additionally, if the context is not empty when you start, your global sequence numbers (or event tokens) will not match, although you can ensure sequencing. The alternative is to use the Axon Server Connector and plug it directly into a stream from Axon Server. On the writing side, you can do the same, which allows you to do more efficient batching of groups of events. You still have the option of transforming events and meta-data, but you can now enforce the sequence numbering is unchanged. Given that Axon Server will complain if a sequence number reuse is attempted, you should ensure no other applications are publishing to the same context.
To use the (new) Axon Server connector, all you need to do is include the coordinates for it in your project:
<dependency>
<groupId>io.axoniq</groupId>
<artifactId>axonserver-connector-java</artifactId>
<version>4.4.5</version>
</dependency>Now you can obtain an event channel to Axon Server:
private EventChannel axonServerConnection(String servers, String context,
String token,
boolean useTls) {
Final String clientId = UUID.randomUUID().toString();
AxonServerConnectionFactory.Builder sourceConnectionFactoryBuilder =
AxonServerConnectionFactory
.forClient("migrationApplication", clientId)
.routingServers(servers)
.token(token);
if (source.tlsEnabled()) {
sourceConnectionFactoryBuilder.useTransportSecurity();
}
return sourceConnectionFactoryBuilder
.build()
.connect(context)
.eventChannel();
}On this channel, you can then either call “openStream()” to read events, or “appendEvents()” to store them. The first lets you pass the global sequence token at which you want to start. The other has a “getLastToken()” to find out how far you were.
Scenario 2: Moving to Axon Server
If you started your application when Axon Server wasn’t available yet, or your company’s standard solutions didn’t include it, you may have an event store in an RDBMS using the Framework’s JpaEventStorageEngine or JdbcEventStorageEngine, or one in MongoDB using the MongoEventStorageEngine. As is discussed in an earlier blog post, these storage engines work reasonably well but are far from ideal given the specific requirements for an “append-only” event store. Migration to an Axon Server cluster would solve that, and a handy migration tool is available for the job. However, if you’re combining it with an upgrade of the application, you could use the programmatic approach as well. It may also be that you’re not able to bring the application down for the migration, in which case you’ll have to use a two-stage process.
The first stage uses the migration tool to move the bulk of the events and snapshots and then continue with a siphoning process that uses a tracking event processor to replay events to the new environment. Note that the migration tool will keep track of its progress, so it can be run several times to catch up before switching to the siphoning approach.
Moving to Axon Server using the Programmatic Approach
If the Migration Tool is not an option, you can also decide to “roll your own” migration utility, which may even be required if your starting point does not use the standard EventStorageEngine implementations. In that case, you can use the programmatic approach as discussed before, using the Axon Server Connector to store events efficiently or publishing through the Framework. Note this also allows you to connect directly to the current Event Store, which gives you access to all necessary meta-data it may provide. Please note that the global sequence number must follow a continuous range, so if the source has gaps, you’ll have to store that number in the meta-data and generate a fresh sequence instead.
Scenario 3: Moving from Axon Server
As should be obvious by now, moving data from Axon Server to another event store will require the programmatic approach, as there are no ready-made tools available. Just as before, you can stream events using a regular handler or else use the Axon Server Connector to read events more efficiently. In a sense, this method can also create human-readable backup copies of the event store, for example, in a JSON format. Combined with a corresponding JSON-to-Axon-Server tool, this would allow for a customized backup implementation, where the storage format is vendor-neutral.
Concluding Remarks
Migrating event data to and from Axon Server in bulk is an activity you should not take lightly, as it generally indicates a large change in your infrastructure. Not discussed in this article is, of course, the simplest approach for creating an off-site backup, which is using a Passive Backup Axon Server node or a pair of Active ones. This will do fine for most disaster recovery requirements, where smaller disasters can be taken care of by having a cluster rather than a single node. If, however, your goal is to migrate data from one event store to another, such as when you first start using an Axon Server cluster, I hope you will now see several available options. For some, we have a ready-made solution available. Please let us know if you think we missed a scenario that needs covering or any other feedback you may have. As always, questions are welcome on our Discuss site, frequented by both the AxonIQ team and many users.

